Splunk에서 신문기사 분석해 보기
Splunk에 수집된 수많은 한글 텍스트 데이터가 있을 때 이걸 어떻게 해야 할까요?
Splunk에서도 간단한 명령어로 쉽게 한글 형태소를 분리해서 문장을 처리할 수 있습니다. Splunk에서 제공하는 custom command 기능을 이용하여 외부의 라이브러리를 사용할 수 있습니다.
여기서 저희는 konlpy 라고 하는 python으로 구현된 형태소 분석기를 Splunk의 명령어로 포팅하여 사용하려고 합니다.
신문기사를 가져오기
신문기사를 가져오는 방법은 여러가지 방법이 있어서 여기서는 따로 언급을 하지 않습니다. 포털에서 뉴스를 가져와서 Splunk에 입력하기 좋은 json형태로 해서 입력합니다.
수집한 뉴스 기사를 바탕으로 구성한 대시보드
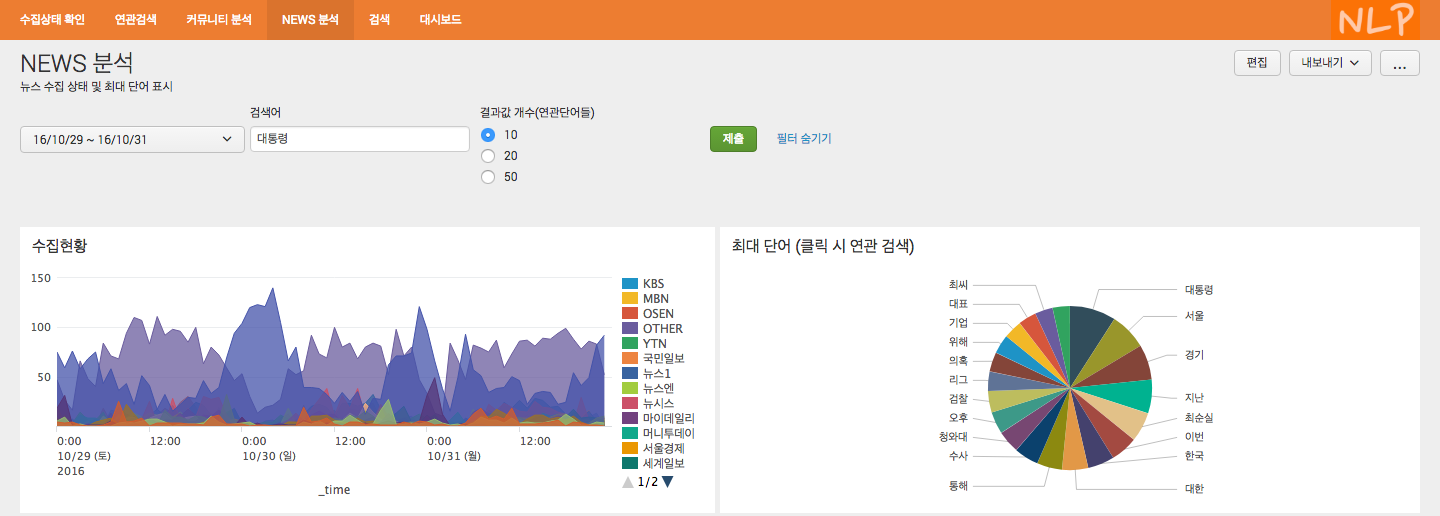
명령어를 이용한 방법 예시
konlpy를 splunk에서 사용할 수 있게 만든 명령어인 konlpy를 이용해서 처리한 예시입니다.
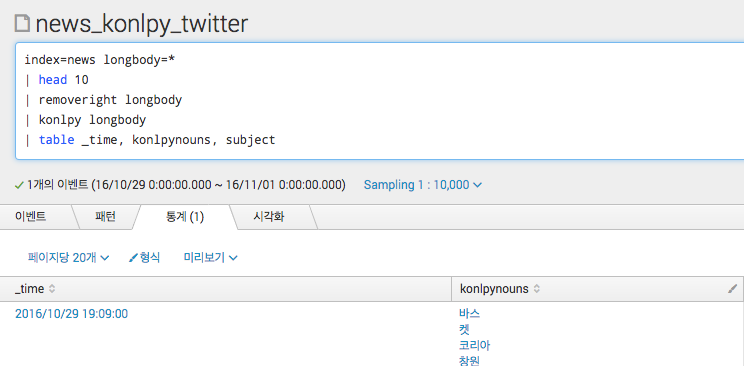
longbody는 본문 필드명이며 본분을 형태소 분석기를 이용해서 분류한 결과를 보고 있습니다. 이런식으로 Splunk내부에서 바로 텍스트의 명사를 분리해서 처리를 할 수 있습니다.
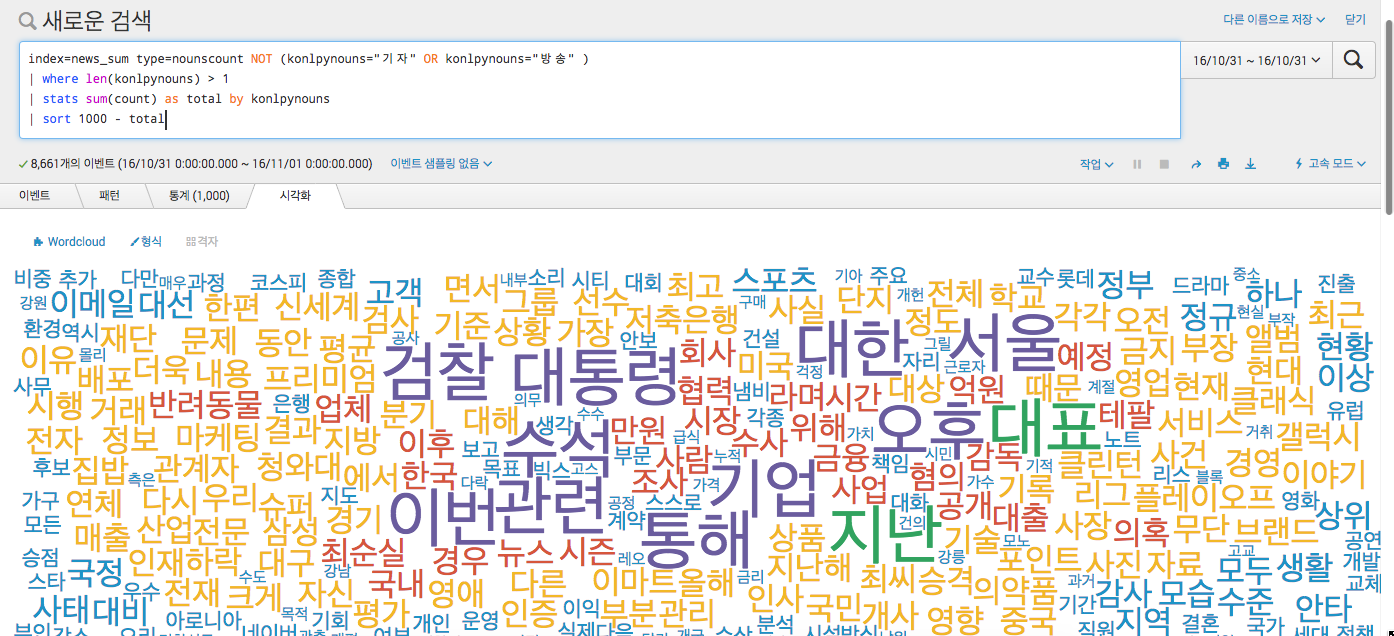
더 나아가면 이런 내용을 이용해서 많이 언급되는 단어들에 대한 wordcloud도 그릴 수 있습니다.